

¡Vamos allá!
En esta primera sesión vamos a ver una introducción a Stata, ¿qué es?, ¿cómo se usa?, etc.
¿Qué es Stata?
Stata es un programa estadístico multiplataforma (es decir, que puede usarse en distintos sistemas operativos: windows, linux, macOS…) creado en 1985. Esto quiere decir que es más moderno que, por ejemplo SAS, SPSS y otros programas que quizás conozcáis. Es intuitivo, rápido y fácil de usar, aunque para operaciones más avanzadas (como el Big Data) puede llegar a ser algo limitado. Además, no es gratuito, frente a otras opciones como R o Python, este es, sin lugar a dudas, su mayor punto débil.
Para vosotros esto de momento no es un problema, la Universidad os facilita ordenadores con Stata instalado y listo para usarse. Sin embargo, aquellos que queráis seguir trabajando con datos en el futuro quizás pensáis en adquirir una licencia.
Sin embargo, tiene varios puntos a su favor, es fácil de usar y desde la versión 11 tiene una GUI (Grafical User Interface) que puede ser de utilidad. No obstante, ya os adelanto que en este curso aprenderemos a usar Stata escribiendo código (o más bien, comandos) y no usando la interfaz gráfica de ventanas. Pero incluso utilizando comandos, Stata es más sencillo de usar que otras opciones ya que no es un lenguaje de programación como tal. Con unos cuantos comandos puedes hacer muchas cosas y no tienes que preocuparte de saber qué es un vector, o qué es una función. A nivel básico Stata es mucho más accesible que los lenguajes de programación que mencionaba.
¿Para qué sirve Stata?
Stata es muy completo, se pueden hacer desde los cálculos más sencillos como sumar y restar:
// Suma con Stata: display 2+4
// Salida: 6
hasta grandes cálculos como modelos de regresión líneal o gran cantidad de gráficos:

Es muy usado en campos como la medicina y las ciencias sociales. En nuestro caso, es ideal para trabajar con bases de datos con registros a nivel individual, de países, etc. Con Stata podemos hacer prácticamente cualquier análisis estadístico que se nos ocurra.
Estructura de la interfaz gráfica
Pero vamos a lo que de verdad os interesa. ¡Abramos Stata!
Todas las capturas y explicaciones usarán la versión de Windows dado que será la que usemos en clase. Aunque veréis la versión 16 y en clase probablemente usemos la 14, pero no hay prácticamente diferencias.
Lo primero que se puede decir de la ventana principal es que tiene en la parte superior (como cualquier programa) la barra de herramientas. En esta barra hay algunos botones que usaremos muy a menudo: el editor de do-files y el editor o visor de datos. Por lo demás, nada interesante porque, como decía más arriba, vamos a aprender a usar comandos y no ventanas.
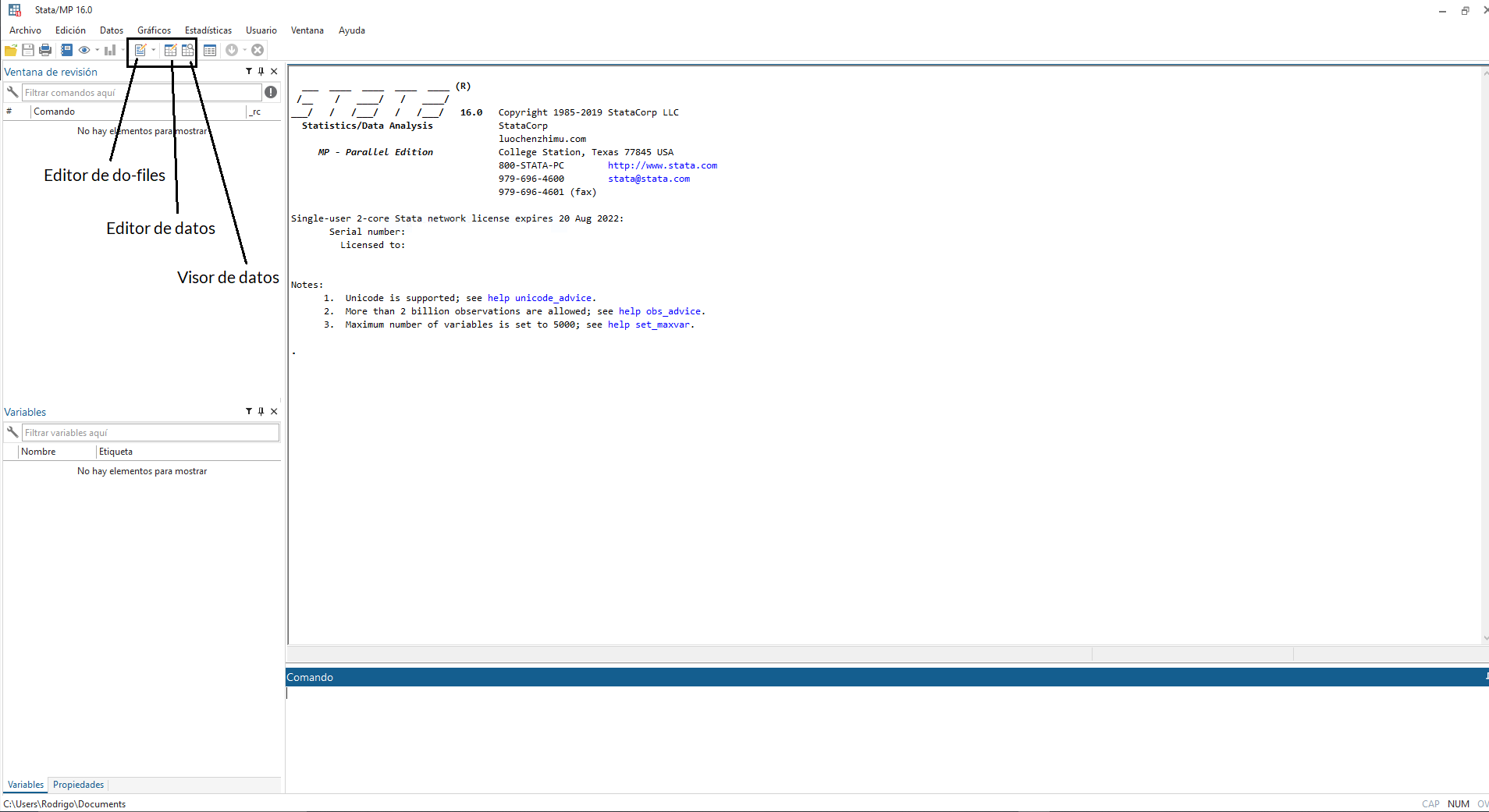
El programa se divide en distintas secciones y tiene distintas posibilidades en cuanto a la organización de estas secciones. Por defecto viene configurado de manera que aparecen las cuatro principales:
- La ventana de revisión
- La ventana de resultados
- La ventana de comandos
- Y la ventana de variables
La apariencia de estas ventanas puede cambiarse en
preferencias/opciones gráficas
La ventana de Revisión
Es una sección muy útil pues nos permite ver cada comando que se ha ejecutado por parte de Stata. Así podemos volver a ejecutar algo anterior o ver si tenemos algún error (aparecerá en rojo).
La ventana de Resultados
Es la que miraremos constantemente para ver las “salidas” del programa, es decir, los resultados de las operaciones que le pidamos a través de los distintos comandos.
La ventana de Comandos
Como su propio nombre indica es la ventana en la que escribiremos los comandos que queramos que Stata ejecute. Sin embargo, veremos que una práctica más recomendable es usar para esto el editor de Do-files (que veremos enseguida).
La ventana de variables
Y finalmente, la ventana en la que aparecen las variables que contiene nuestra base de datos. Hasta ahora no tenemos ninguna base de datos cargada, luego no tenemos ninguna variable en esta ventana. Así que, carguemos alguna.
![]()
Lo más interesante para que podamos empezar cuanto antes a familiarizarnos con la base de datos de Quality of Government es que la descarguemos de aquí.
Lo primero que debes saber es en qué formato descargarla, para usarla con Stata, debe ser el archivo con extensión .dta. A partir de ahora ya sabes cuál es la extensión de los archivos que contienen datos para usar directamente en Stata. No obstante, Stata puede leer también archivos CSV y en formato xls (Excel), como veremos más adelante.
Antes de cargar la base de datos en Stata vamos a abrir el editor de Do-files.
¿Qué es un Do-file?
¿Te imaginas comenzar a pedirle a Stata que haga complejísimos cálculos a través de la ventana de comandos, por ejemplo: que recodifique una variable, que calcule la media, la desviación típica y que luego haga una tabla cruzando los valores con los de otra variable y que cuando termines todas esas instrucciones sólo sirvan una vez? Sería muy tedioso tener que volver a escribir lo mismo cada vez que quieras que Stata haga algo que vas a querer volver a pedirle. Para eso existen los Do-files.
Básicamente un do-file es un archivo con extensión .do que sirve para escribir comandos con la sintaxis de Stata y guardarlo para poder ejecutarlo completo o por partes en cualquier momento.
Es por este motivo por el que usaremos el editor de do-files y no la ventana de comandos. Así, todos los comandos que escribas en clase quedarán guardados para volver a ejecuarlos cuando quieras.
Lo primero que suele escribirse en un do-file (por ser ordenados, simplemente) es una serie de datos sobre quién lo ha escrito y qué contiene el archivo, por ejemplo:
****************************************** ** Nombre: Sesión 1. Introducción a Stata ** Asignatura: Evolución y Teoría del Estado ** Autor: Rodrigo Fernández ****************************************** // Código a partir de aquí
Es totalmente opcional y de hecho, esto no incluye ningún comando que vaya a ejecutar Stata aún. Cuando incluímos un asterisco delante del texto Stata entiende que lo que viene a continuación es un comentario y no un comando. Es decir, que se lo va a “saltar” y no va a ejecutar nada.
Hay varias formas de hacer comentarios en un do-file:
** Esto es un comentario de una línea // Esto también es un comentario de una línea /* Esto es un comentario que puede ocupar varias líneas */
Y a partir de aquí empezamos con los primeros comandos:
Para trabajar con Stata primero hay que decirle al programa cuál será nuestro directorio de trabajo. Por defecto siempre se coloca en C:\users\documents. Para cambiarlo usamos el siguiente comando:
cd "C:/users/tu_usuario/documents/Stata/sesion1" //Para windows cd "Users/tu_usuario/Documents/Stata/sesion1" // Para sistemas UNIX
Una vez situados donde queremos trabajar (hay que crear antes el directorio si no existe) podemos cargar la base de datos que descompimiremos en esta ruta.
** También es buena practica que añadáis estas opciones al empezar el do-file: clear all // Limpia la memoria RAM antes de empezar set more off // Evita la paginación por defecto de Stata, para evitar que se quede parado cuando ejecutes un comando que ocupe mucho en la ventana de resultados. ** Para cargar una base de datos en formato .dta: use qog_std_cs_jan20
Ahora, para ejecutar el do-file podemos pinchar en el siguiente botón (run):
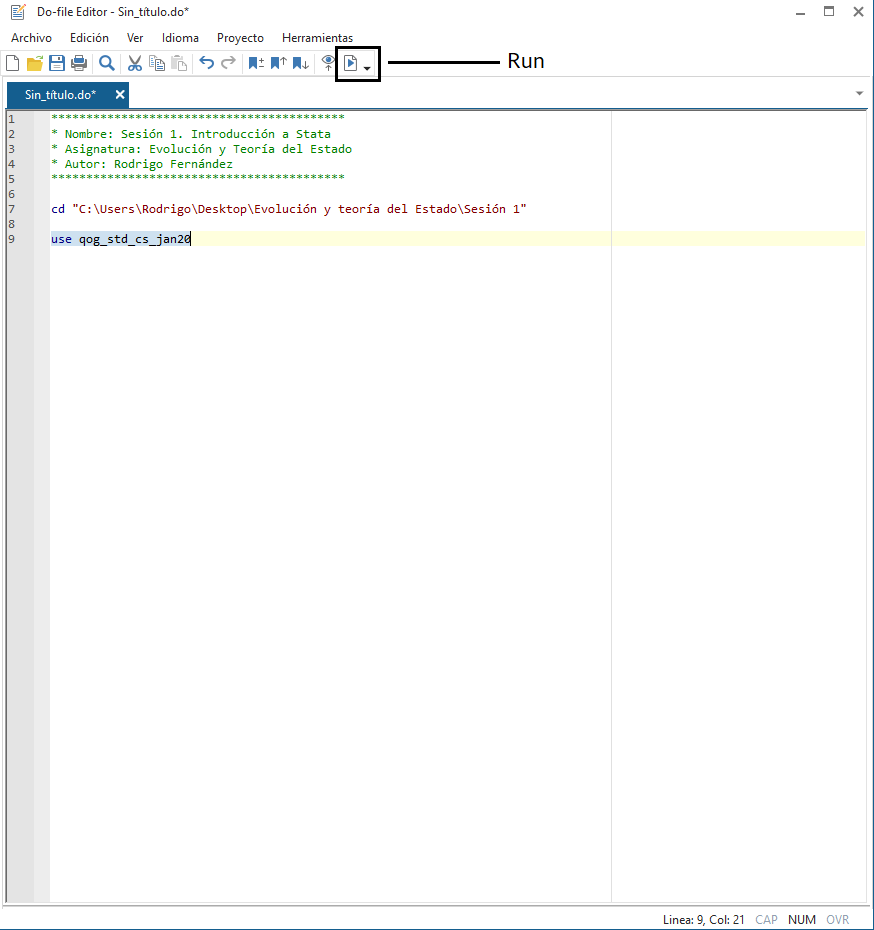
o, mejor aún, utilizar el atajo de teclado ctrl+D en windows o cmd+D en mac.
ATENCIÓN: Esto ejecuta todas las líneas del do-file. Ahora no nos importa pero cuando vayamos escribiendo más código no querremos que Stata ejecute todos los comandos. Para evitarlo, selecciona con el ratón sólo lo que quieras que se ejecute y pulsa
ctrl+D
Si te fijas, en la ventana de variables han aparecido las variables de QoG y en la ventana de resultados Stata muestra los comandos que ha ejecutado desde el do-file.
¡Ya podemos empezar a trabajar!
Lo primero que es interesante hacer cuando trabajamos con una base de datos es ver cómo es la base de datos, es decir, ver los propios datos. Vamos a ejecutar nuestro primer comando, que sirve para ver en una tabla (como una hoja de cálculo de excel) los datos que Stata ha cargado en memoria:
// Abre la ventana del visor de datos browse
Stata carga los datos en la memoria RAM del ordenador para poder trabajar con ellos. Eso quiere decir que hace una copia de los datos que hay en tu disco duro. Aprenderemos a usar estos datos a partir del archivo dta sin sobreescribirlos, así una vez terminemos de trabajar, cerraremos Stata, se vaciará la memoria, pero nuestro archivo original estará intacto.
Esta es la pinta que tiene la base de datos de QoG:
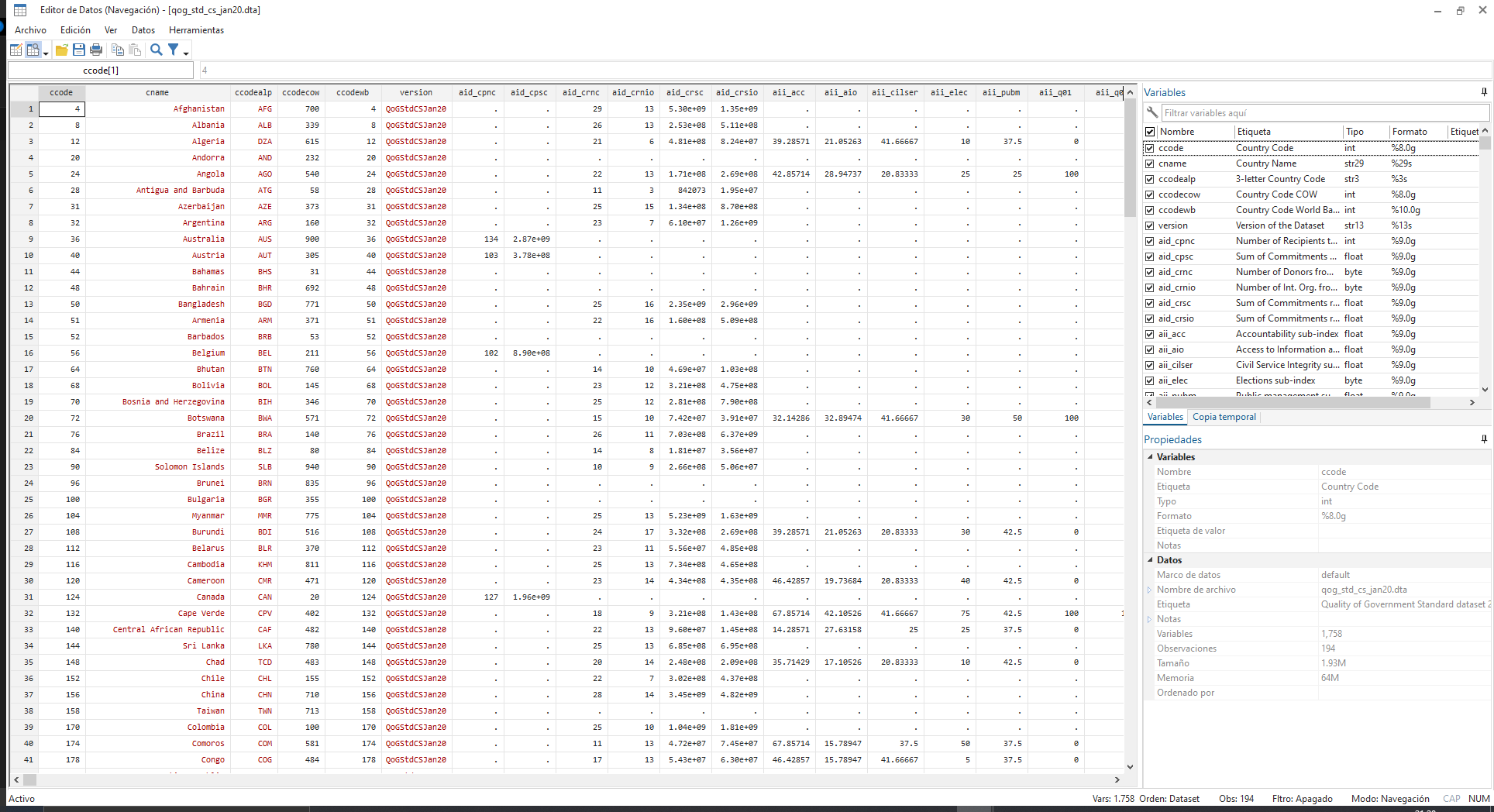
Lo primero que podemos ver es que es una matriz de filas y columnas. Pues bien, las filas son las observaciones y las columnas las variables. Eso quiere decir que si la base de datos tiene 1000 observaciones tendremos 1000 filas y cada fila tendrá un valor (o ninguno) para cada columna (variable). Pero, como era de esperar, las variables no son todas iguales porque los datos que guardan las variables son de distinta naturaleza.
No vamos a ver en profundidad los tipos de datos ya que esto corresponde más a un curso de ingenieria de software o ingeniería informática. Pero es importante que sepáis qué tipos básicos de datos existen y por qué Stata los “pinta” de manera distina.
Como veis en el visor de datos hay tres colores.
- Rojo: Son variables de tipo string o cadena de texto. Es decir, contienen texto plano, no números.
- Azul: Son variables categóricas, es decir, que representan categorías, por ejemplo: hombre, mujer… Sin embargo, se pintan en azul si tienen asignadas unas etiquetas. Atención: el valor almacenado en la variable NO es el de la etiqueta en azul, sino un número. Si pinchas sobre uno de los valores podrás ver arriba a qué valor corresponde esa etiqueta.
- Negro: Pueden ser dos tipos de variables. Las que denominamos continuas, es decir, números al uso; y las categóricas que no tienen etiquetas.
Lo bueno de que Stata pinte con colores las variables es que de una manera muy visual podemos saber de qué tipo son y así saber cómo tratarlas. Por ejemplo, no podremos hacer cálculos con una variable que tenga valores en rojo, porque esa variable contiene texto plano y no números. Y, a la inversa, no podremos pedirle a Stata que muestre el texto de una variable que en realidad contiene números. Más adelante, no obstante, veremos con más detalle qué diferencias hay dentro de las variables numéricas y categóricas. Por ahora, me sirve con que entendáis que Stata trata de manera distinta a estos tres tipos principales.
Ahora que tenemos datos cargados en memoria, cerremos esta ventana y empecemos a usar comandos útiles en el do-file. Un comando muy útil también a la hora de empezar a trabajar con una base de datos es el siguiente
** Nos da información general sobre la base de datos: describe
Como véis aparece una lista larguísima con detalles sobre los tipos de datos que contienen las variables, el nombre de éstas el formato, etc.
Empecemos por pedirle a Stata que nos muestre una tabla de frecuencias de la variable. En el siguiente post veremos qué información nos da esta ventana porque lo primero es entender qué tipo de datos existen y cómo los interpreta Stata.